海纳澎湃算力于方寸
重构万物智能向云端


云边端大模型框架
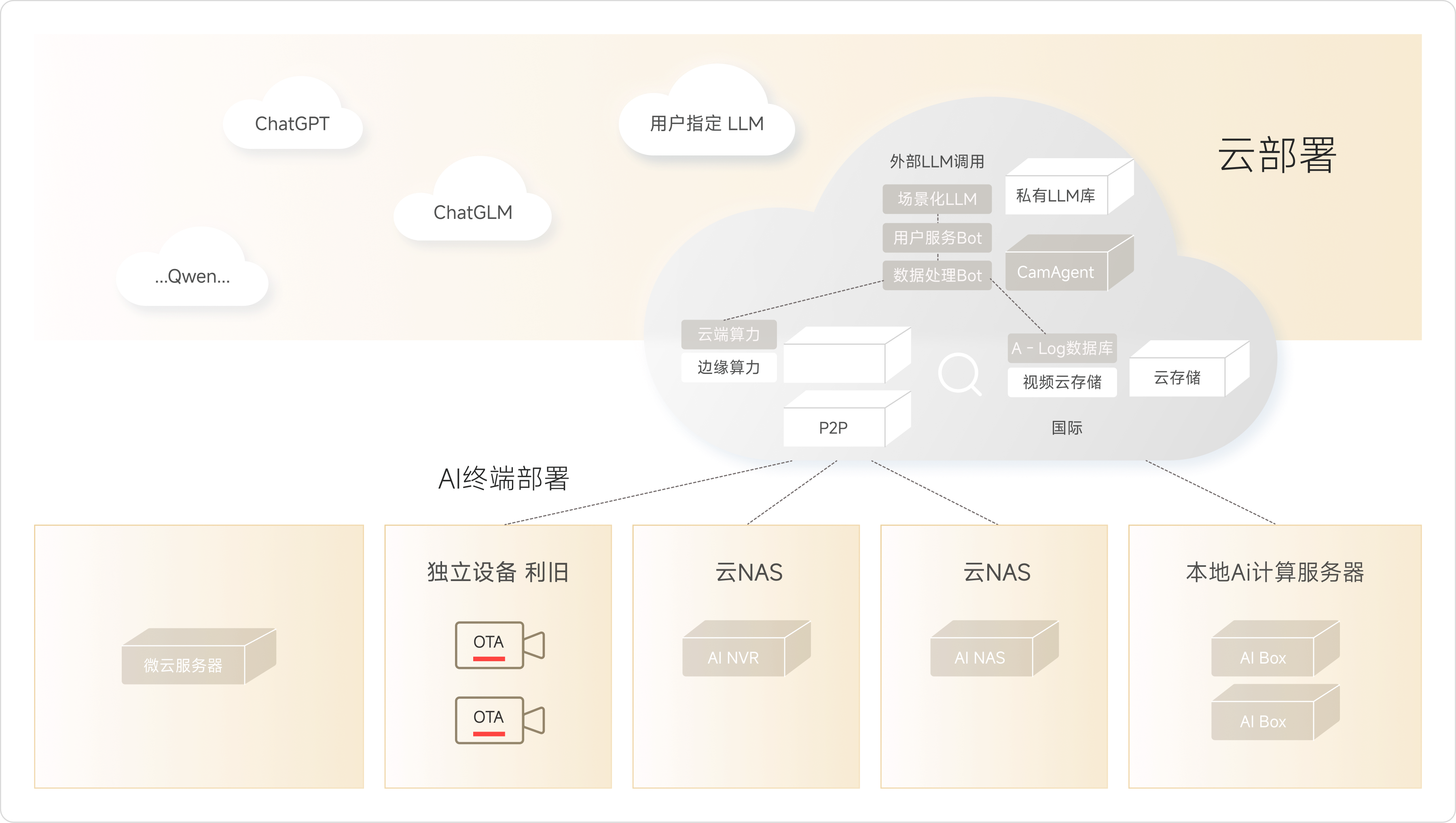
算法模型兼容性

从端侧来看,清微智能边缘端量产芯片支持各类适配初筛场景的轻量 CNN 模型,其内置的可重构 AI 引擎可灵活兼容初筛所需的高召回率模型,满足端侧实时响应的核心需求。而在云端,清微智能基于可重构计算架构推出的 RPU 芯片单个模组,能够轻松承载千亿级参数的 VL 大模型(如已完成适配的 DeepSeek - R1 模型),为云端二次复核提供强大算力支撑,精准消除误报(如区分火焰与橙色干扰物、跌倒与正常躺卧)。
清微智能凭借其深厚的技术积淀,在算法支持层面与端云协同检测方案形成高度适配。方案中端侧轻量模型(如火焰检测、跌倒算法实时初筛)及云端视觉大模型(VL用于二次复核),均能在清微智能的芯片产品体系中高效运行。
算力精度与重构优势

算力精度匹配
方案中,端侧初筛对算力精度要求相对灵活,清微智能边缘端芯片支持 int4、int8、int16 等量化精度,可根据轻量模型需求灵活选择,在保证检测灵敏度的同时降低功耗。端到端性能对标国际一流厂商旗舰产品,能完美适配 VL 大模型的高精度计算需求。可重构算力提升效率
清微智能核心的可重构计算技术(CGRA),通过将神经网络计算图拆解出的不同类型算子映射到计算阵列,构建灵活的硬件互联结构,形成可按需调配的算力资源。在端云协同方案中,这种重构能力可实现矩阵计算与向量计算模块的并行运作,同时支持计算与数据传输并行。例如,端侧芯片在处理初筛时,可通过可重构架构同步完成图像特征提取(向量计算)与目标初步识别(矩阵计算),大幅提升 响应的稳定性;云端 TX81 芯片在进行二次复核时,并行算力可快速处理关键帧数据,缩短复核耗时,且能根据不同场景的风险等级,动态调整算力分配,适配复核阈值的变化。

成本、功耗与布局:适配场景需求的硬件优势
清微智能芯片通过技术创新实现成本控制,与方案 “优化成本” 的核心价值高度契合。从端侧来看智能视觉芯片系列已实现量产,规模化生产降低了硬件采购成本,且其可重构架构无需为不同初筛模型单独定制芯片,进一步减少硬件适配成本。在云端,清微智能 REX1032 训推一体服务器支持训推一体,不仅能满足 VL 大模型的推理需求,还可实现模型蒸馏训练,用户无需单独采购训练与推理设备,大幅降低硬件投入。 同时,方案中 “大模型仅处理<10% 初筛样本” 的设计,结合清微智能芯片的高能效比,可减少云端算力消耗,降低长期运营成本(如电力、维护成本)。 结合清微智能技术特点后,端云协同火焰 & 跌倒检测方案的优势得到进一步强化,具体对比数据如下:
